AI compression sounds promising—what would “better” even mean for your system?
You can cut a file in half and still lose money if your p95 response time goes up or your CPU bill spikes. That’s the trap with “AI compression”: it sounds like one knob, but most systems pay in three places—stored bytes, bytes over the wire, and work per request to encode/decode.
“Better” has to be stated in your terms: smaller at the same quality, same size at higher quality, faster time-to-first-byte, lower decode CPU, or lower energy on edge devices. Each target pulls you toward different methods and different risks, like requiring new formats, extra hardware, or retraining models when your data shifts.
Before tools, define the bill you’re trying to shrink.
The first decision: are you paying for bytes, time-to-first-byte, or compute per request?
That “bill” usually shows up in one of three lines: bytes, time-to-first-byte, or compute per request. If finance keeps flagging S3 and CDN egress, you’re paying for bytes. In that case, you can tolerate a slower encoder and even some extra decode work—as long as the payload shrinks enough to matter at your traffic level.
If product is watching p95 and abandonment, you’re paying for time-to-first-byte. Smaller helps, but only if the client can start decoding fast. A format that saves 20% but adds a new init step, a bigger header, or a slower first frame can lose in practice. Teams often discover this only after rolling to low-end phones or busy edge nodes.
If your AWS bill is dominated by per-request CPU (or battery on-device), decode cost is the constraint. Learned methods often shift work around, so the only safe move is to name where the work runs—server encode, edge transcode, or client decode—before asking where “AI” even fits.
Where AI actually enters compression (and where it doesn’t)
Once you name where the work runs, you can separate “AI compression” into a few concrete patterns. The most common is still classic: you keep JPEG/AV1/Zstd, but use a model to make the input easier to compress—denoise images before encoding, predict residuals, or pick per-chunk parameters more aggressively. You didn’t change the decoder, so rollout risk stays low.
The harder jump is learned end-to-end coding, where an encoder network maps content into latents and a paired decoder reconstructs it. That can win on certain media distributions, but it usually means a new bitstream, new tooling, and strict versioning so old clients can still decode. If your fleet includes low-end devices, the decoder alone can wipe out the byte savings.
Then there’s “efficiency” that isn’t compression at all: distilling a model, caching, or sending embeddings instead of raw data. Useful, but it changes what you’re transmitting—and what correctness even means.
When learned methods beat classic codecs—and the telltale signs in your data
If the decoder can wipe out the byte savings, learned methods only win when your data gives them room to be simpler than the classic pipeline. You’ll usually see that in “narrow” content distributions: the same camera sensor and lighting patterns, one game engine’s render style, repetitive UI screenshots, or telemetry payloads with stable schemas. In those cases, a learned encoder/decoder can spend fewer bits on structure it already “expects,” while JPEG/AV1/Zstd still pay overhead to stay general.
The telltale signs show up in your existing experiments. If rate-distortion curves flatten early for your current codec (you keep spending bits but quality barely improves), or if your artifacts are consistent and content-specific (the same banding in sky gradients, the same blockiness in thin text), that’s a hint your codec’s assumptions don’t match your data. Another clue is heavy post-processing today—denoise, deblock, or “sharpen”—which often means you’re compensating for a mismatch after the fact.
The constraint is operational: those wins can vanish when your content mix shifts. A seasonal change in imagery, a new device, or a UI redesign can force retraining and revalidation before you can safely ship the next model version.
Operational reality check: training data, hardware, and format lock-in

That retraining and revalidation work is where “AI compression” stops being a graph and becomes a pipeline you have to run on schedule. In practice, you need a stable, labeled-enough corpus that matches what you’ll ship: the new phone camera, the new UI theme, the new sensor firmware. If you can’t log representative samples (privacy, cost, retention limits) or you can’t keep them long enough to reproduce a bug, you’ll struggle to debug quality regressions and you’ll end up arguing from screenshots.
Then there’s hardware reality. Training needs GPUs, but serving is where it bites: decode on low-end Android, in a browser sandbox, or on an edge CPU has tight limits. A decoder that’s “fast on A100” can still be a non-starter on a midrange phone, and quantization can change artifacts in ways your QA team hasn’t built muscle for.
Finally, new bitstreams create lock-in. Once clients depend on a custom decoder, you inherit versioning, fallbacks, and long-tail device support—so the next question is whether the efficiency claim is actually fewer bytes, or just moving work into places you don’t currently measure.
Compute efficiency claims: is it compression, model distillation, or just moving work around?
That “moving work” shows up fast when a vendor promises “3× efficiency” but your bandwidth chart barely moves. Sometimes the gain is real compression: fewer bytes stored or sent at the same quality. Just as often it’s distillation or quantization: the model gets smaller or cheaper to run, but outputs stay the same size. Or it’s caching and precompute: you pay once upstream so requests look cheap downstream.
Pin each claim to a location and a unit. If “faster” means GPU milliseconds at encode time, ask what happens to client decode CPU, time-to-first-byte, and battery. If “smaller” means “we send embeddings,” ask what you can no longer do with the raw data, and how you validate correctness when a downstream task changes.
The hard part is measurement discipline: cost can disappear from one team’s dashboard and reappear in another’s. A pilot only works if you instrument both ends before you change the format.
A low-risk pilot you can defend: what to measure, what to ask, what to ship
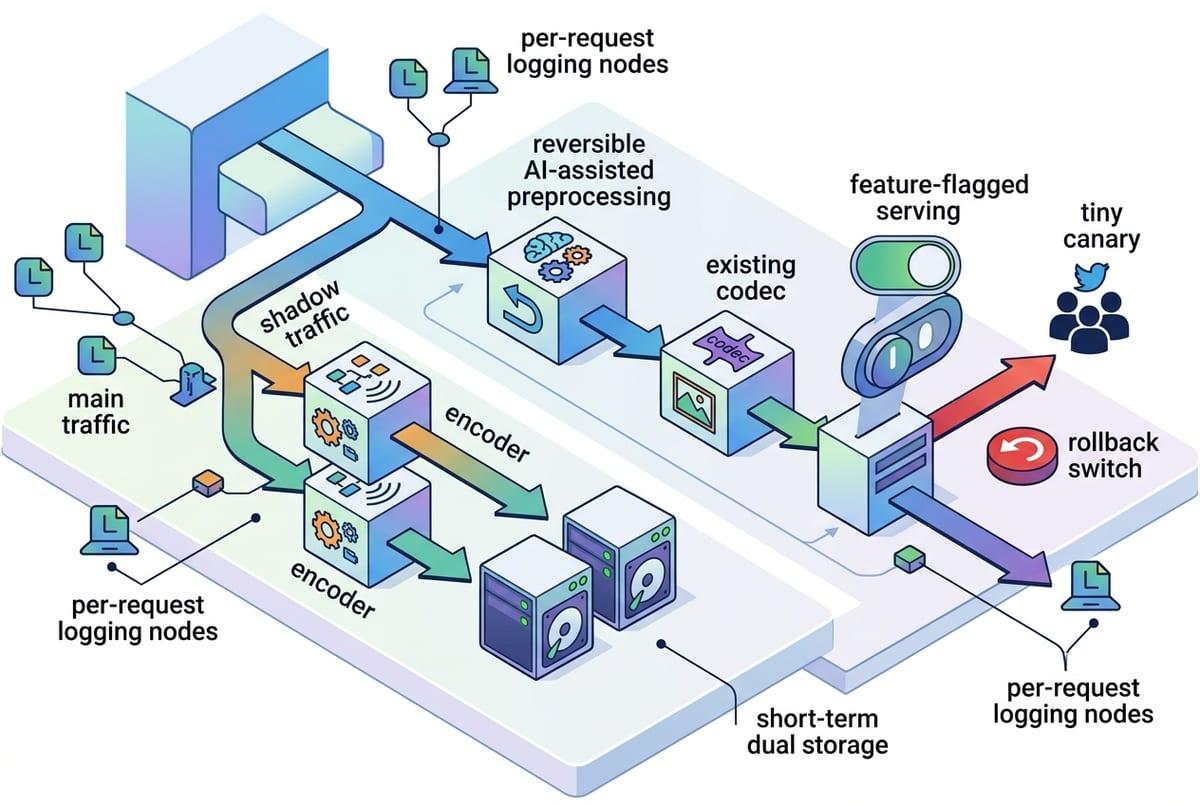
That instrumentation is what keeps a pilot from turning into a format migration by accident. Start by running a shadow path on real traffic: encode both ways, store both outputs for a short window, and serve the new path only to internal users or a tiny canary. If it’s media, measure size, time-to-first-byte, first-frame time, steady-state decode CPU, and device battery proxy (temperature, frequency throttling, dropped frames). If it’s telemetry, measure end-to-end ingest latency, decompression CPU, and error rates under backpressure.
Ask questions that force location and failure modes. What hardware was used for the quoted encode/decode numbers? What happens on your worst 10% devices and on a busy edge CPU? How do you version decoders, and what’s the rollback plan if quality regresses on one model update? What does “same quality” mean—PSNR/SSIM, task accuracy, or human review—and who signs off?
Ship the smallest reversible change: AI-assisted pre-processing or parameter selection feeding your existing codec, with a feature flag and per-request logging. Save the new bitstream until you can prove the wins survive real clients and real content shifts.
You don’t need a bet-the-farm codec swap—start with the constraint you can prove
That “prove the wins” is the point: you don’t need to replace your codec to get leverage. If your constraint is egress, start with AI-assisted parameter tuning or pre-filters that keep JPEG/AV1/Zstd decoders unchanged, then show a real traffic-weighted dollar delta. If your constraint is p95 or battery, focus on faster decode paths, even if the files get slightly bigger, and validate on the slowest client class you support.
The difficulty is scope creep. A custom bitstream pulls in rollout logic, long-tail device bugs, and a permanent compatibility burden. Treat learned end-to-end coding as the last step, not the first. Pick one bill, one surface area, one week of canary data, then decide whether the win is durable enough to carry format risk.