You were promised “anomaly detection”—what problem is it actually solving?
You buy “anomaly detection” because you want fewer outages, chargebacks, late shipments, or scrap—but what you’re really buying is a way to rank “this looks different than usual” and decide when “different” deserves a page. In practice, teams use it for three jobs: catching sudden spikes (fail fast), flagging slow creeps (fail quietly), and surfacing weird one-offs (rare, messy cases). Every false alert steals attention, and every miss becomes a postmortem with your name on it. Before tools, you need to name what “normal” means in your process.
Define “normal” in your process (and who pays when you’re wrong)

That definition of “normal” is where most anomaly projects win or die: in the real world, normal changes by hour, day, region, customer mix, or line speed. If your payment volume jumps every Friday, a detector that expects flat traffic will page you weekly. If your factory switches suppliers, the “normal” vibration profile shifts, and yesterday’s safe threshold can turn into today’s constant alarm.
So write “normal” as a set of expectations tied to the decisions you’ll make. What metric, at what granularity, over what window, and what action follows? Then assign the cost of being wrong. If a false positive wakes an on-call engineer, that’s expensive fast. If a false negative means shipping bad units for two hours, that’s worse. You can’t tune sensitivity without naming who eats each mistake.
Once you can price errors, you’re ready to see why boring baselines often beat fancy models at the start.
When simple baselines outperform AI in the first month
Boring baselines usually win first because they match how teams actually work: you need a stable signal before you need a clever model. A rolling average with day-of-week seasonality, a simple control chart, or a threshold that adapts to volume often catches the same “something changed” moments you care about—without weeks of tuning. If your metric is “failed payments per 1,000 attempts,” a baseline that normalizes by traffic prevents the classic 2 a.m. page caused by a harmless volume spike.
AI tends to lose that first month on setup costs. You still have to pick features, handle missing data, align timestamps, and decide what counts as an incident. If you can’t explain an alert in one sentence, the on-call will stop trusting it.
Start with the baseline, then use the gaps it exposes to justify the model you actually need.
What models are actually doing when they “spot anomalies”
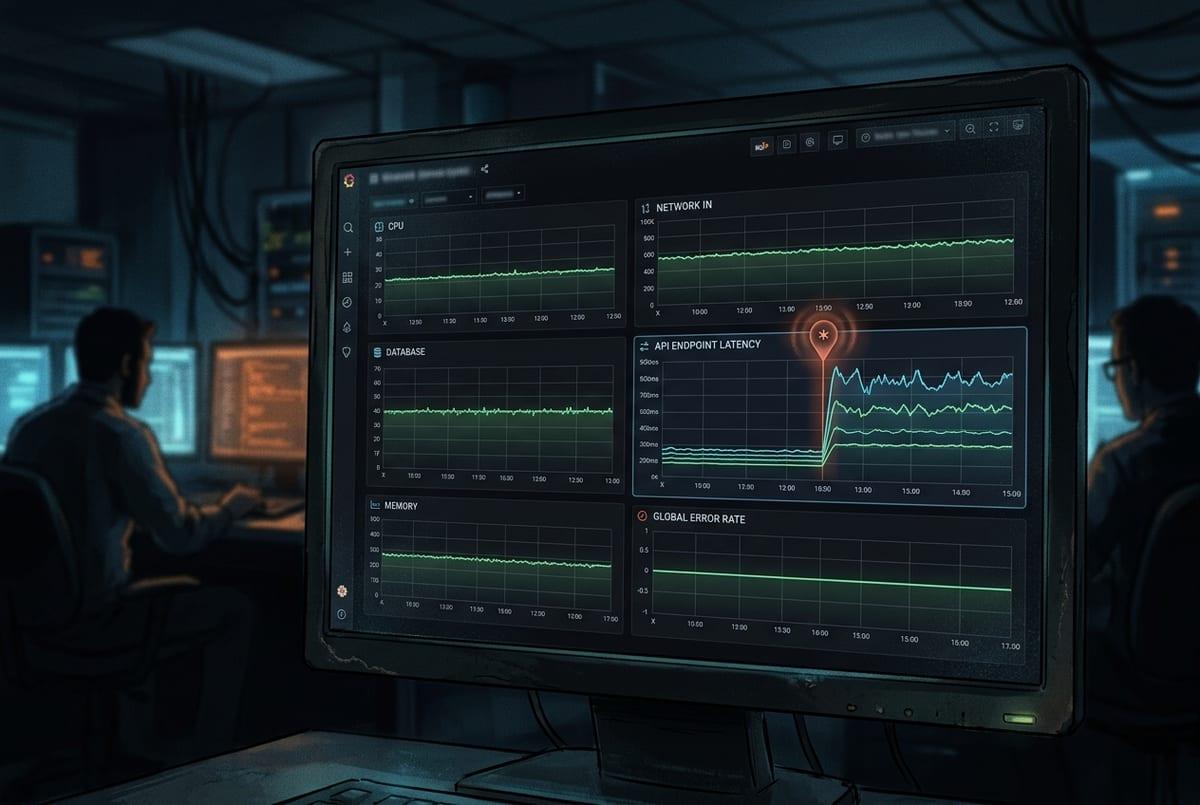
Those gaps usually show up as “the baseline looks fine, but something still feels off”—like error rates staying flat while a few endpoints slow to a crawl, or a shipping lane that starts missing SLAs only for one carrier and one warehouse shift. Most anomaly models don’t “recognize incidents.” They compute a score for “how unlikely is this pattern given what I’ve seen,” then you choose a cutoff.
In plain terms, there are a few common moves. Forecasting models predict the next value and alert on a big residual; they break when seasonality changes or the input data lags. Density or distance methods learn where most points live in feature space and flag outliers; they get noisy when you add weak features (like dozens of lightly used metrics) because distance stops meaning much. Reconstruction models (often autoencoders) learn to compress normal behavior and alert when they can’t rebuild it; they can quietly learn bad “normal” if incidents are frequent.
None of these tells you what to do. If you can’t tie a high score to a concrete decision—rollback, reroute, stop-the-line—you’ll just buy a faster way to create alerts.
Why it missed the incident (or flooded you with alerts)
That’s how you end up with a faster way to create alerts: the score moves, but the cutoff doesn’t match how your incidents actually show up. If the detector watches aggregated “error rate,” a real incident that hits one endpoint or one region can hide inside the average. If it watches too many metrics, small, harmless wobbles stack up and look “unlikely,” so you get a burst of pages every time traffic shifts or a batch job runs.
Misses often come from training on the wrong “normal.” If last quarter included chronic slowdowns, a reconstruction or density model can absorb them as acceptable. Floods often come from plumbing, not math: late data, backfills, clock skew, and missing fields create patterns the model never saw, so it fires constantly until you fix ingestion.
Before tuning, you need a way to tell “real incident” from “weird but fine”—which is where the label problem starts.
Labels are scarce—so what data do you need to start anyway?
That label problem usually shows up as a spreadsheet nobody has time to finish: a few memorable incidents, a long tail of “maybe,” and months where nothing was written down. Most teams don’t have clean anomaly labels, so you start by collecting “decision labels” instead. For each alert or candidate event, record what you did (paged, rolled back, ignored), how long it took to confirm, and the impact (minutes of downtime, dollars, units scrapped). That gives you a usable target: “worth interrupting someone” versus “noise.”
To get there, you need data with context, not just metrics. Keep raw values plus the denominators you normalize by (attempts, volume, machine cycles), and capture the slices where incidents hide (region, endpoint, carrier, line, shift). Preserve timestamp accuracy and missing-data flags; otherwise your “anomalies” will just be late feeds. Instrumenting join keys, fixing schemas, and backfilling history often takes longer than model training.
Once that logging is in place, drift becomes obvious—and painful.
Drift happens: the moment your process changes, does the detector break?
Drift shows up the first time you change something on purpose: you deploy a new checkout flow, reroute orders to a new carrier, swap a supplier, or speed up a line. The detector then treats “new normal” as suspicious, so you either get a week of noise or you raise thresholds and miss the next real issue. This isn’t a corner case; most operations change faster than models get retrained.
Plan for drift like you plan for releases. Keep a changelog of known shifts (feature flags, pricing changes, maintenance windows) and tag your data with those states so you can compare like-with-like. Watch two dashboards: alert volume and the distribution of key inputs (latency mix, traffic sources, sensor ranges). If either shifts sharply, assume the model is stale until proven otherwise.
A pilot plan that proves value without risking the farm
That “turn it off” rule is the spine of a safe pilot: treat the detector as a decision aid, not a paging system. Start in shadow mode for 2–4 weeks—score events, but don’t wake anyone—then replay the top alerts against your incident log and ask, “Would we have acted sooner?” If you can’t answer in one sentence, it doesn’t ship.
Limit scope hard: one process, one or two metrics with clear denominators, and a small set of slices where incidents hide (region/endpoint/line). Set a fixed alert budget (for example, 5/day) and measure precision as “percent of alerts that led to a real action.” The real cost is review time: someone must triage every alert for the pilot to mean anything.
Only after it clears those gates do you let it page, and even then behind routing rules (business hours, severity thresholds, auto-silence during releases). If it can’t stay stable through one planned change, it’s not ready for production.