The demo works—then the first real traffic spike hits
The demo feels clean: one endpoint, a few test prompts, acceptable speed. Then real users arrive at once—an email blast, a Slack integration rollout, a seasonal spike—and the same model starts timing out, queuing, or returning inconsistent answers.
What changes isn’t the model; it’s the shape of traffic and the system around it. One slow request can block a worker, retries multiply load, and GPU utilization can look “fine” while p95 latency climbs. If you’re renting GPUs, you’ll also learn a blunt fact: you can’t buy half a card for a half-busy hour.
What are you actually shipping: latency promise, quality bar, or cost ceiling?
In a production rollout, the first argument usually isn’t about model choice; it’s about what you’ll tell the business when something has to give. If your product needs “feels instant” chat, you’re shipping a latency promise, which means you’ll spend budget on headroom, stricter timeouts, and aggressive fallbacks when queues form. If you’re shipping a quality bar—“must be right,” “must cite,” “must follow policy”—you’ll accept slower paths like longer context, retrieval, or second-pass checks, and you’ll pay for the extra tokens and compute.
If you’re shipping a cost ceiling, you’re defining unit economics up front: dollars per conversation, per document, per agent action. That forces hard choices like smaller models, shorter outputs, or routing only the toughest queries to the expensive path. The practical downside is user-visible inconsistency: two customers can get different latency or depth because your router is trying to protect the budget.
Pick the primary constraint, then measure the other two as consequences—otherwise you’ll tune blindly and still miss the p95.
When your GPUs idle but users still wait: diagnosing the serving stack
Missing the p95 usually means the bottleneck isn’t “the model,” it’s the path around it. The familiar symptom is maddening: GPUs show 40–60% utilization, yet users stare at spinners because requests sit in a queue, a single-threaded preprocessor backs up, or you’re blocking on a vector DB call before you ever reach decode.
Start by splitting latency into stages you can name: request parse/auth, prompt building, retrieval, tokenization, queue wait, model prefill, token streaming, post-processing, and logging. If queue wait dominates, your concurrency limits or worker model are wrong for bursty traffic. If prefill dominates, long contexts or too many concurrent sequences are choking memory bandwidth. If streaming is slow, your network path or gateway buffering may be batching “by accident.”
The annoying part: the fix can live in three different repos, and you’ll spend a week just adding tracing. Once you can see each stage, you can choose where to buy headroom and where to cut work.
Why cost jumps in steps (and why it feels unpredictable)

Once you can see each stage, the next surprise is that cost doesn’t rise smoothly with traffic. It rises in chunks, because most of what you buy comes in fixed units: a full GPU, another replica, a larger node class, a higher throughput tier on a managed store. You can run at 30% load for hours, but the bill still reflects 100% of the capacity you reserved for the spike you fear.
That’s why it feels unpredictable: small traffic changes push you over thresholds. A slightly longer average prompt can cut your effective concurrency, so you add a replica “just for p95,” and your monthly spend jumps. A new feature adds retrieval calls, and you hit a vector DB rate limit, so you scale that service too. The cost increase looks like “the model got expensive,” but it’s often a chain reaction across dependencies.
The hard part is that autoscaling usually reacts after queues form, so you pay twice: in user-visible latency, then in stepped-up capacity. The next move is learning which workload shapes you can smooth on purpose.
The first lever you’ll regret ignoring: batching, caching, and request shaping
Smoothing the workload on purpose usually starts with three unglamorous knobs: batching, caching, and request shaping. In the wild, requests don’t arrive evenly—they clump—so if you serve each one immediately, you waste GPU time on setup work and create more queue churn than you need.
Batching fixes that by letting the server group compatible requests during prefill, then stream tokens out per user. Done well, p95 drops and throughput rises; done carelessly, you add a few dozen milliseconds of waiting and your “feels instant” chat gets sluggish. Caching buys bigger wins when users repeat work: store retrieval results for the same query, reuse prompt templates, and cache partial model outputs for common system instructions. The catch is invalidation. If your docs or policies change daily, stale cache can ship the wrong answer.
Request shaping is the guardrail: cap max tokens, trim context, rate-limit retries, and reject oversized prompts early, so one customer can’t force you to scale the whole fleet.
You need faster and cheaper—how much model quality are you about to trade away?
Once you’ve capped tokens, shaped retries, and squeezed batching, the remaining way to get faster and cheaper is to do less work per request. In practice, that means a smaller model, a compressed model (distillation), or a model that runs with lower-precision weights (quantization). Each option can hold up in a demo prompt set, then fail in production on the messy tail: long instructions, edge-case domains, or “please follow policy” prompts where a small drop in compliance becomes a real support burden.
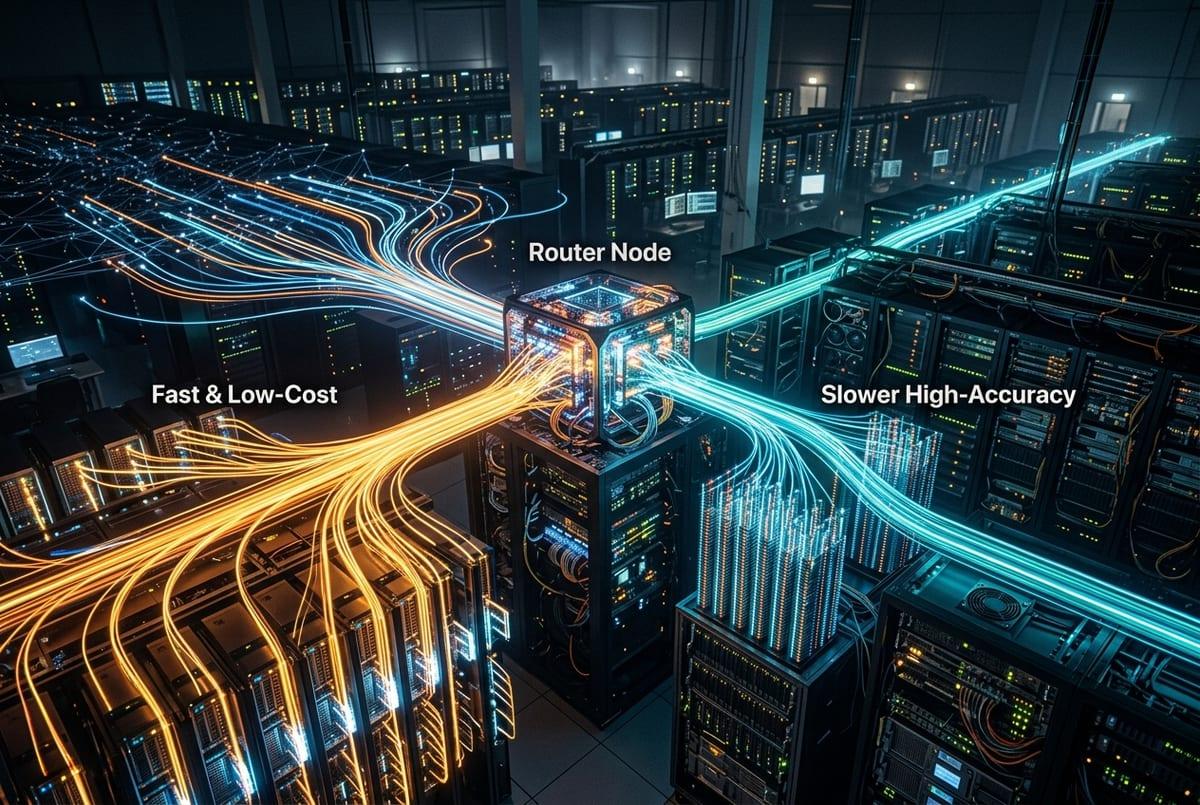
Make the trade in the open. Pick 20–50 “can’t be wrong” scenarios—your highest-risk intents, your longest contexts, and your most common user flows—then compare candidates on those, not on average scores. If a quantized model saves 30% latency but increases tool-call retries, your end-to-end cost can rise anyway because the system does more total work.
If you can’t afford the best model everywhere, route by difficulty—and accept the engineering cost of keeping that router honest.
Capacity planning that won’t collapse the day usage doubles
Keeping that router honest becomes harder the day traffic doubles, because your “average” no longer matters—your tail does. Plan around p95 concurrency, not daily volume: estimate tokens/sec per GPU for your chosen context lengths, then reserve headroom so one burst doesn’t turn into a retry storm. Run a load test that replays real prompt sizes and retrieval calls, and bake those traces into alerts for queue depth, time-to-first-token, and dependency latency, not just GPU utilization.
The constraint you’ll hit first is usually cold start and scaling lag. New replicas take time to load weights, warm caches, and reconnect to stores, so reactive autoscaling can protect cost while still failing users. If you can’t keep spare capacity, use a deliberate degrade path—shorter max output, smaller fallback model, or “try again” gating—so you fail predictably instead of melting down.